PDF Accessibility
Évaluation du balisage
Avant de baliser un document, il est essentiel d’évaluer et de préparer le PDF pour garantir qu’il puisse être rendu accessible. Ce processus comprend plusieurs étapes clés, notamment la vérification du contenu du document. Une préparation adéquate aide à simplifier le processus de balisage et garantit que le document final respecte les normes d’accessibilité.
Qu’est-ce que les XObjects ?
Les XObjects dans les PDF sont des objets graphiques réutilisables qui permettent un rendu et un stockage efficaces. Ils incluent des Form XObjects (graphismes vectoriels, texte ou images) et des Image XObjects (images bitmap). Les XObjects sont définis une seule fois et peuvent être référencés plusieurs fois dans le PDF, réduisant ainsi la taille du fichier et garantissant une représentation visuelle cohérente. Ils sont particulièrement utiles pour les dispositions complexes, les éléments répétitifs et l'intégration de contenu externe.
Lors de la création d'un document accessible, les XObjects peuvent poser des défis importants, car le contenu qu'ils contiennent est souvent regroupé en un seul élément, ce qui rend le balisage difficile. Voici quelques solutions pour résoudre ces problèmes :
Comment baliser les figures et images XObject
Le balisage des éléments XObject peut entraîner plusieurs problèmes tels que des erreurs de syntaxe, des erreurs visuelles ou des problèmes avec le PAC (PDF Accessibility Checker). Pour éviter ce type de problème, certaines actions peuvent être réalisées dans le panneau de contenu.
- Identifier l'élément xObject pertinent
- Localisez l'élément xObject qui cause des problèmes. Il est important d’isoler l’élément spécifique pour éviter des modifications non intentionnelles sur d'autres parties du PDF.
- Encapsuler l'xObject dans une balise "Artifact"
- Créez un conteneur Artifact pour isoler en toute sécurité l'élément XObject :
- Faites un clic droit sur n’importe quelle balise dans le panneau des balises.
- Sélectionnez Nouvelle balise de conteneur et entrez "Artifact" comme type de balise.Remarque : La nouvelle balise Artifact apparaîtra initialement comme enfant de la balise sur laquelle vous avez cliqué. Déplacez-la à un emplacement approprié dans l'arborescence des balises.
- Ensuite, déplacez l’élément XObject identifié dans la balise Artifact nouvellement créée.Right-click on any tag in the Tags panel
- Créez un conteneur Artifact pour isoler en toute sécurité l'élément XObject :
- Baliser ou supprimer l'élément selon les besoins
- Balisez-le comme nécessaire.
- Ou supprimez-le directement depuis le panneau des balises.
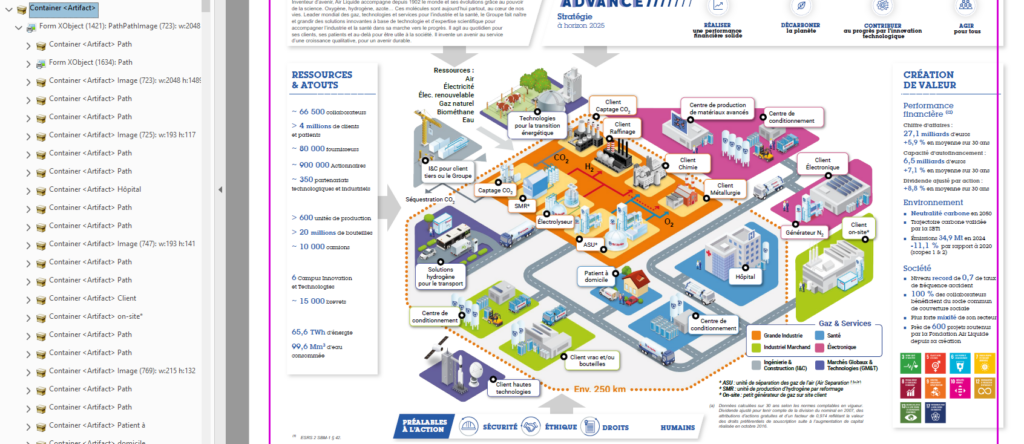
Ça devrait ressembler à ça
Remarque :
- Assurez-vous toujours que l'intégrité du document est préservée.
- Cette méthode pourrait ne pas fonctionner pour les éléments de texte ou de tableau. Pour ces types d'éléments, les méthodes ci-dessous seraient plus efficaces.
- Vérifiez toujours avec PAC lorsque vous modifiez des XObjects, car ils sont très spécifiques et volatils.
Comment corriger.
Conversion du document en utilisant Distiller
Une méthode efficace pour résoudre les problèmes liés aux XObjects est d'utiliser le processus de distillation pour le PDF. Cette approche permet de flattening le contenu du document, garantissant que chaque élément soit représenté individuellement plutôt que d’être regroupé ensemble.
- Exporter le document en PostScript
- Ouvrez votre document PDF dans Adobe Acrobat.
- Exporter en PostScript :
- Allez dans Fichier > Exporter vers > PostScript.
- Choisissez un emplacement pour enregistrer le fichier PostScript (.ps).
- Sauvegardez le fichier avec l'extension .ps.
- Lancer Acrobat Distiller
- Configurer les préférences :
- Dans Acrobat Distiller, allez dans Modifier > Préférences.
- Sous Paramètres Adobe PDF, assurez-vous que l'option Incorporer les polices est activée. Cela garantit que les polices sont intégrées dans le PDF pendant le processus de conversion.
- Choisissez une option de Job appropriée, comme Haute qualité d'impression ou Qualité presse, en fonction de la qualité de sortie souhaitée.
- Configurer les préférences :
- Ajouter le fichier PostScript
- Faites glisser et déposer le fichier PostScript (.ps) que vous avez sauvegardé précédemment dans la fenêtre Acrobat Distiller, ou utilisez Fichier > Ouvrir pour localiser et sélectionner le fichier.
- Vérifier les corrections des XObjects
- Ouvrez le nouveau PDF créé dans Adobe Acrobat Pro.
- Vérifiez le document pour confirmer si les XObjects ont été correctement supprimés.
Conseils supplémentaires
- Bien que cette méthode soit efficace pour supprimer les XObjects, elle peut également avoir des inconvénients, notamment en affectant l'apparence visuelle du document. Il est donc essentiel de vérifier minutieusement le document pour s'assurer qu'il reste visuellement intact après le traitement.
- Bien que la distillation d’un document soit très efficace, elle peut aussi introduire des problèmes d’encodage des polices. Lorsque vous évaluez l’efficacité de cette méthode, gardez à l'esprit que l’encodage des caractères peut être corrigé, mais le processus ne doit pas être trop chronophage. Si trop d'erreurs nécessitent des corrections manuelles importantes, il peut être plus efficace d'explorer des solutions alternatives pour résoudre les erreurs liées aux XObjects.
Découper et copier
Cette méthode consiste à extraire et à réappliquer le contenu dans le XObject.
Étape 1 : Ouvrir le PDF dans Adobe Acrobat Pro
- Lancez Adobe Acrobat Pro.
- Ouvrez le PDF contenant les problèmes liés aux XObjects.
Étape 2 : Sélectionner le XObject
- Allez dans l'outil Modifier dans la barre d'outils ou utilisez l'option Modifier le PDF depuis le panneau des outils.
- Cliquez sur le XObject ou le contenu que vous suspectez d'être regroupé en tant que XObject.
Étape 3 : Découper le XObject
- Faites un clic droit sur le contenu sélectionné et choisissez Couper dans le menu contextuel.
Alternativement, appuyez sur Ctrl+X (Windows) ou Command+X (Mac).
Le XObject sera temporairement supprimé et stocké dans le presse-papiers.
Étape 4 : Coller le contenu
- Faites un clic droit à l'endroit même où le XObject a été supprimé et sélectionnez Coller.
Alternativement, appuyez sur Ctrl+V (Windows) ou Command+V (Mac).
Cette action réinsère le contenu en tant qu'objet modifiable et balisable, plutôt qu'un XObject regroupé.
Étape 5 : Vérifier le contenu
- Vérifiez que le contenu collé apparaît correctement et reste visuellement intact.
- Utilisez les outils d’accessibilité d'Acrobat pour confirmer que le contenu est désormais sélectionnable et peut-être correctement balisé.
Étape 6 : Répéter pour les autres XObjects
- Si le document contient plusieurs XObjects, répétez le processus pour chaque élément problématique.
Conseils supplémentaires
- Toujours créer une copie de sauvegarde de votre PDF original avant de faire des modifications, car cette méthode altère la structure du document.
- Lors du collage du contenu dans le document, utilisez les outils d'alignement d'Acrobat pour garantir que le contenu est placé précisément à l'endroit où il se trouvait à l'origine.
- Après avoir collé, vérifiez que le nouveau contenu ne se chevauche pas avec d'autres éléments ou ne cause pas de problèmes de mise en page.
- Utilisez l'outil Vérification de l'accessibilité d'Acrobat pour confirmer que le contenu nouvellement ajouté est dorénavant balisable et accessible.
- Pour les XObjects contenant des images regroupées ou des dispositions complexes, envisagez de les diviser en sections plus petites avant de les réappliquer.
- Copier-coller plusieurs fois peut dégrader la qualité de l'image ou perturber la mise en forme. Essayez de minimiser les actions répétées.
- Si vous travaillez sur un grand document, concentrez-vous sur une page ou une section à la fois pour garder le contrôle et éviter les erreurs.
- Après avoir réappliqué le contenu texte, assurez-vous qu'il soit sélectionnable et correctement encodé pour l'accessibilité.
- Une fois toutes les modifications effectuées, vérifiez l'intégralité du document pour détecter d'éventuels problèmes visuels ou structurels non intentionnels.
Qu'est-ce que l'encodage des caractères ?
L'encodage des caractères définit la manière dont les caractères, tels que les lettres, les chiffres et les symboles, sont représentés et stockés dans un PDF. Il garantit que le texte est affiché correctement et peut être extrait, recherché ou traité de manière fiable.
Les normes d'encodage courantes, comme Unicode, prennent en charge une large gamme de caractères, tandis que d'autres, comme ASCII, gèrent des ensembles de caractères de base. Un encodage précis est crucial pour maintenir l’accessibilité et garantir le bon fonctionnement du texte dans les PDF.
Causes
Les problèmes d'encodage des caractères peuvent survenir dans des situations spécifiques, telles que :
- Paramètres d'exportation incorrects lors de la génération du PDF.
- Polices manquantes sur le système.
- Polices non intégrées dans le PDF.
- Problèmes liés à la langue ou aux caractères spéciaux.
Comment corriger
Voici quelques méthodes pour résoudre ces types de problèmes :
Outil Preflight pour réparer les problèmes de police
L'outil Preflight dans Adobe Acrobat est utilisé pour analyser et valider les fichiers PDF afin de détecter des problèmes potentiels, tels que des problèmes de polices, des incohérences de couleurs et des corruptions de fichiers. Il offre des profils préconfigurés et des options personnalisables pour corriger diverses erreurs de document, garantissant la conformité aux normes comme PDF/A et améliorant l’accessibilité du document ainsi que la qualité d'impression.
- Ouvrir le PDF dans Adobe Acrobat Pro :
- Lancez Adobe Acrobat Pro et ouvrez le document PDF présentant des problèmes liés aux polices.
- Accéder à l'outil Preflight :
- Allez dans le panneau Outils en haut à gauche.
- Faites défiler vers le bas et cliquez sur Production d'impression.
- Dans les outils de Production d'impression, sélectionnez Preflight.
- Sélectionner un profil Preflight :
- Dans la fenêtre Preflight, vous verrez une variété de profils préconfigurés.
- Pour résoudre les problèmes de polices, développez les sections Conformité PDF/A ou Polices. Vous pouvez également rechercher "polices" dans la barre de recherche du panneau Preflight pour trouver des profils spécifiques liés aux polices.
- Lancer un contrôle des polices :
- Si vous dépannez des polices manquantes ou non intégrées, vous pouvez choisir le profil Polices : Polices manquantes ou non intégrées.
- Sélectionnez ce profil et cliquez sur le bouton Analyser.
- Acrobat analysera le document à la recherche de polices manquantes ou non intégrées.
- Corriger les problèmes de polices :
- Après la fin de l’analyse, Acrobat fournira un rapport listant tous les problèmes de police.
- Si des polices sont manquantes ou non intégrées, vous pouvez les corriger en sélectionnant l'option Corriger, qui intégrera les polices dans le PDF.
- Vérifier les corrections :
- Réouvrez le PDF corrigé et vérifiez que toutes les polices sont désormais correctement affichées et intégrées.
- Vous pouvez également relancer l'outil Preflight pour confirmer qu’il ne reste aucun problème de police.
Conseils supplémentaires
- Substitution de polices : Si Preflight détecte des polices manquantes, il peut les remplacer par des polices système disponibles. Assurez-vous que les polices souhaitées sont intégrées pour préserver l'apparence originale du document.
- Utilisation des profils Preflight : Acrobat propose divers profils pour différents types de corrections de documents. Vous pouvez créer des profils personnalisés si vous devez fréquemment traiter des problèmes spécifiques.
Utilisation d'Acrobat Distiller
Acrobat Distiller est un outil d'Adobe Acrobat qui permet de convertir des fichiers PostScript (.ps) en documents PDF. Il permet aux utilisateurs d'appliquer des paramètres spécifiques pour la qualité de sortie, tels que l'intégration des polices et la compression, garantissant ainsi que le PDF résultant soit correctement formaté et conserve l’apparence souhaitée.
- Exporter le document en PostScript
- Ouvrir le document dans Acrobat :
- Ouvrez votre document PDF dans Adobe Acrobat.
- Exporter en PostScript :
- Sélectionnez Fichier > Exporter vers > PostScript.
- Choisissez un emplacement pour sauvegarder le fichier PostScript (.ps).
- Enregistrez le fichier avec l'extension .ps.
- Ouvrir le document dans Acrobat :
- Lancer Acrobat Distiller
- Configurer les préférences :
- Dans Acrobat Distiller, allez dans Modifier > Préférences.
- Sous Paramètres Adobe PDF, assurez-vous que l'option Incorporer les polices est activée. Cela garantit que les polices seront intégrées dans le PDF lors du processus de conversion.
- Choisissez une option de Job appropriée, comme Haute qualité d'impression ou Qualité presse, selon la qualité de sortie souhaitée.
- Configurer les préférences :
- Ajouter le fichier PostScript :
- Faites glisser et déposer le fichier PostScript (.ps) que vous avez sauvegardé dans la fenêtre Acrobat Distiller, ou utilisez Fichier > Ouvrir pour localiser et sélectionner le fichier.
- Vérifier l'intégration des polices et la qualité du PDF
- Après que Distiller ait terminé le traitement du fichier, ouvrez le PDF résultant dans Adobe Acrobat.
- Allez dans Fichier > Propriétés > Polices pour vous assurer que toutes les polices sont correctement intégrées et listées comme "Intégrées" au lieu de "Substituées".
Conseils supplémentaires
- Assurez-vous que les polices sont installées : Vérifiez que toutes les polices utilisées dans le document sont disponibles sur votre système avant d'exporter en PostScript pour éviter les problèmes de polices manquantes.
- Incorporation des polices : Si les polices ne sont pas intégrées, vérifiez à nouveau les paramètres d'Acrobat Distiller pour vous assurer que l'option d'insertion des polices est activée.
Qu'est-ce que l'OCR (Reconnaissance Optique de Caractères) ?
Le contenu OCR fait référence au texte présent dans un document qui ne peut pas être directement sélectionné ou interactif, car il existe souvent sous forme d'images intégrées dans le PDF. Ces images agissent comme des espaces réservés pour le texte, mais elles n'ont pas la fonctionnalité des vraies couches de texte.
Par exemple, le document peut contenir des pages scannées ou du texte basé sur des images qui doivent être convertis en texte sélectionnable et lisible avant que le balisage ne puisse être effectué. Cette conversion est généralement réalisée à l’aide d’un logiciel OCR, qui analyse le contenu du document et génère une couche de texte pouvant ensuite être balisée et rendue accessible.
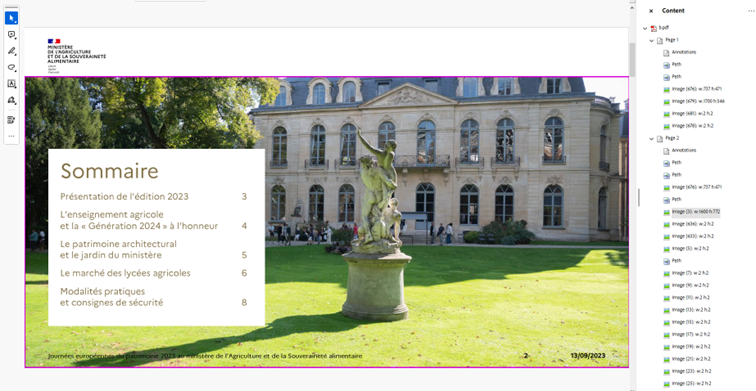
Comment corriger
Comme montré dans l'exemple ci-dessus, le contenu peut sembler visuellement normal dans le PDF ; cependant, après un examen plus approfondi, il devient évident que le texte est en réalité composé de chemins ou d'images plutôt que de texte sélectionnable. Cela signifie que le contenu n'est pas intrinsèquement accessible et nécessitera un traitement OCR pour le convertir en une couche de texte modifiable et balisable. Cela signifie également que le contenu ne peut pas être sélectionné directement.
Lorsque cela se produit, deux solutions s'offrent à nous :
Demander un nouveau document ou la source native
Si le document contient du contenu non sélectionnable, comme du texte basé sur OCR ou des images, il peut être nécessaire de demander une nouvelle version. Contactez le client et demandez-lui de fournir soit une version mise à jour du document, soit le fichier source natif (par exemple, Word, InDesign, etc.) afin qu'une nouvelle version accessible puisse être générée. Cela aidera à garantir que le document soit correctement formaté et prêt pour le balisage, le rendant ainsi accessible à tous les utilisateurs.
Utiliser la fonction OCR d'Acrobat
Utilisez la fonction OCR (Reconnaissance Optique de Caractères) dans Adobe Acrobat pour détecter et convertir le texte visuel présent dans le document en contenu réel et sélectionnable. Ce processus transforme tout texte basé sur des images ou scanné en une couche de texte, le rendant ainsi accessible et prêt pour le balisage. Une fois l'OCR appliqué, le texte peut être édité, balisé et traité pour répondre aux normes d'accessibilité.
- 1. Ouvrir le PDF dans Adobe Acrobat :
- Lancez Adobe Acrobat et ouvrez le fichier PDF contenant du contenu basé sur des images ou scanné.
- 2. Activer l'outil OCR :
- Allez dans le menu Outils en haut à gauche.
- Dans le panneau des outils, sélectionnez Scan & OCR. Si vous ne le voyez pas, cliquez sur Plus d'outils pour le localiser.
- Une fois dans l'outil Scan & OCR, cliquez sur Reconnaître le texte.
- 3. Choisir les paramètres OCR :
- Après avoir cliqué sur Reconnaître le texte, sélectionnez Dans ce fichier dans le menu déroulant.
- Une boîte de dialogue apparaîtra avec divers paramètres. Vous pouvez choisir :
- Langue : Sélectionnez la langue du texte dans le document pour une reconnaissance précise.
- Style de sortie : Choisissez Image recherchable (Exact) ou Image recherchable (Compact). L'option Exact conserve l'image originale tout en ajoutant la couche de texte, tandis que l'option Compact tente de compresser la sortie.
- 4. Démarrer le processus OCR :
- Une fois les paramètres sélectionnés, cliquez sur Reconnaître le texte pour lancer le processus OCR.
- Acrobat traitera le document et tentera de détecter le texte dans les images ou les pages scannées, le convertissant en texte sélectionnable et recherchable.
- 5. Vérifier les résultats de l'OCR :
- Une fois l'OCR terminé, vous pouvez vérifier le document pour vous assurer que le texte a été correctement reconnu et converti.
- Vous pouvez maintenant sélectionner, copier et éditer le texte selon vos besoins.
Conseils supplémentaires
- Précision de l'OCR : L'OCR ne sera pas toujours 100 % précis, notamment en cas de scans de mauvaise qualité ou avec des polices inhabituelles. Il est donc important de vérifier et de corriger manuellement les erreurs éventuelles.
- Nettoyage des images : Si le document contient des images complexes ou des arrière-plans bruyants, il est recommandé de nettoyer les images avant d'appliquer l'OCR pour obtenir de meilleurs résultats.
- Format du document : Si vous avez le fichier source natif (par exemple, Word, InDesign), il est préférable de le demander au client, car l'OCR ne fournit pas toujours des résultats parfaits, notamment pour des formats complexes.